Projects don't start with clarity. They start with whatever the client has accumulated: docs, threads, decks, notes that made sense to whoever wrote them. Turning that into something structured enough to design against is real work. It's also repetitive, mechanical, and identical across every engagement.
That's not design work. That's parsing. A machine should do it.
What arrives. What always arrives.
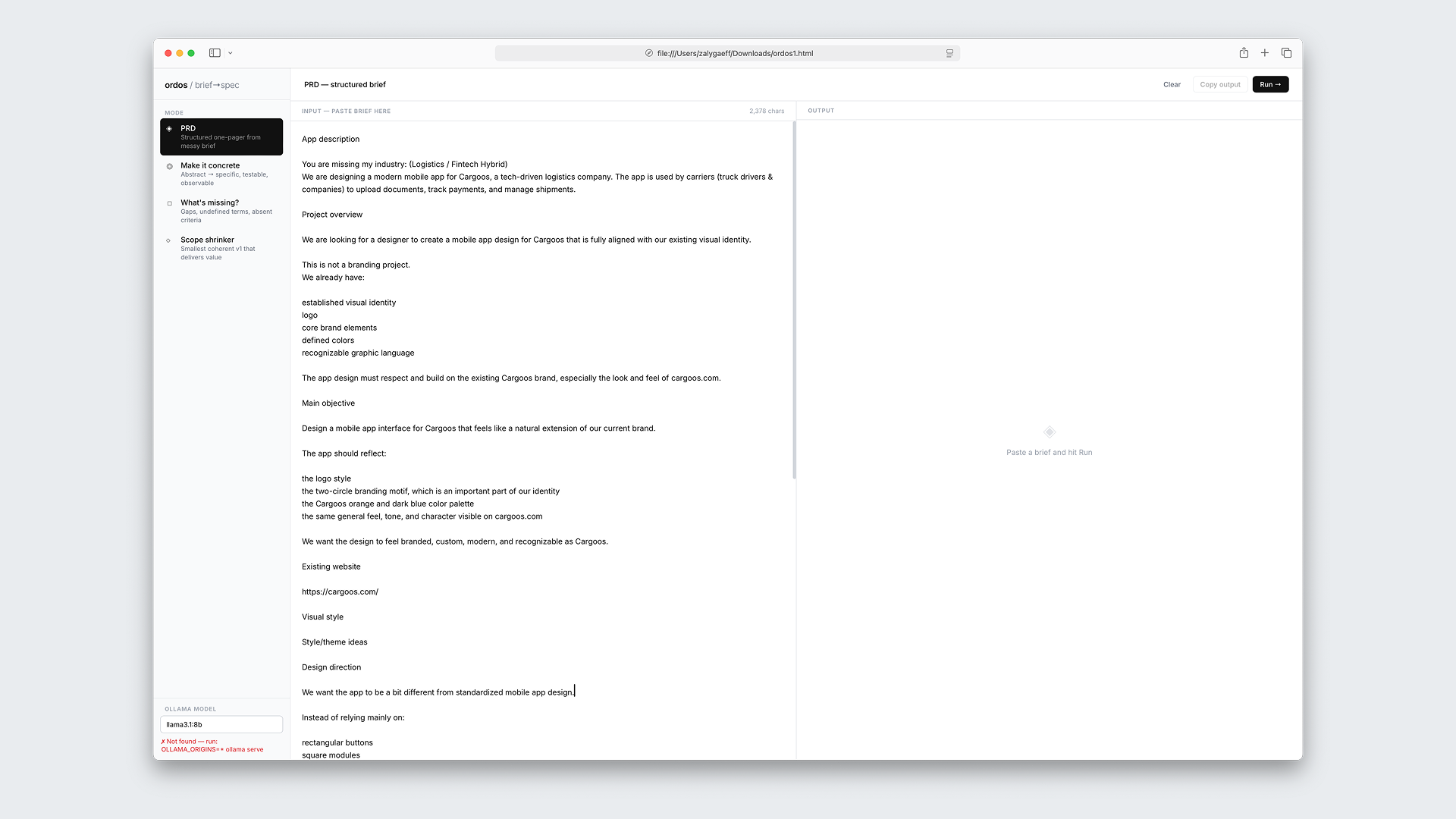
First version
Started as a random thought: what if the extraction work could be automated. Not the thinking, just the formatting. I sat with Claude and explored it for a while. No spec, no wireframe. Just a conversation that gradually shaped into something: four modes (generate, make it concrete, what's missing, scope shrinker), plain text in, structured text out, local inference so I'm not paying to validate a hunch.
Claude built a working prototype. I used it. It confirmed the core idea: even a rough tool that forces structure onto messy notes saves real time. It also confirmed that the execution wasn't there yet. Four modes sitting side by side with no hierarchy, no clear workflow between them. A proof of concept, not a product.
I backlogged it. Moved on to other things. The idea stayed good. The prototype didn't deserve a second week of attention.
Version one. Functional. Forgettable.
What changed
When I came back to it, I worked on two tracks in parallel. In Figma, exploring how it might look: layout, typography, the visual language of the modes. In Claude, building a mock prototype to test whether the layout ideas actually held up with content in them. The prototype went through several structural shifts in the conversation before anything was settled.
The linter replaced the gap analysis mode. "What's missing?" as a mode you activate means you only see the gaps when you ask. The linter runs on every section as it generates, without being asked. Annotations next to the sentence they apply to are impossible to skip. That's the difference between a quality gate and a quality habit.
Modes became parallel. Stress Test and Scope Shrinker split the right panel with a vertical divider: artifact with linter on the left sub-panel, mode output on the right. Both visible at the same time.
Stress test roles are characters, not titles. "Person who uses a spreadsheet and is perfectly fine" not "end user." "Founder who built almost exactly this and pivoted" not "entrepreneur." A title gives you a perspective label. A character gives you a voice and a reason to disagree. The difference in output quality is significant.
Questions as flowing text, not bullet lists. Empty-state sections show guiding questions as plain lines of text. Some of them overlap intentionally. Approaching the same topic from multiple angles is how you get a useful answer, not a complete-sounding one.
Appetite as a parameter, not a form. The Scope Shrinker's time budget sits in the panel header as part of the interface, not as a separate configuration step. You set it and the analysis reshapes around it.
Spec and critique, same screen.
Working with Claude on specs
Claude proposes features with total confidence and zero accountability. During the Ordos spec it suggested a context selector and a rationale sidebar. Both came with convincing arguments. Both got prototyped. Both turned out to be unnecessary once I actually used them.
This happens constantly. Claude generates ideas that sound smart and survive first-pass scrutiny. The problem is that first-pass scrutiny is exactly where most AI-assisted spec work stops. If you don't build the thing and use it, you ship features that exist because they sounded reasonable, not because anyone needed them.
How it was built
Claude for the spec. Figma for the design. Claude Code for the build.
Getting pixel-perfect design via prompts is genuinely terrible. Claude Code builds architecture and logic reliably, but it can't read designs accurately enough, and without a Developer MCP to bridge Figma and code, you're stuck describing what's wrong in words. Most of the refinement was inspecting what it built, explaining the problem, and repeating. It took longer than the architecture work.
Same stack as Rei: single-file HTML, vanilla JS, Ollama, localStorage. No build step, no framework. A static folder and a terminal command.
What came out the other end.
Where it is now
I use it occasionally. The idea proved out: paste a mess, get a structure, see the gaps. That loop works and saves real time when it runs.
The output needs tuning. It's too verbose. A compiled PRD should be tighter than what the model currently produces, more signal per sentence. That's a prompt engineering problem, solvable but not solved yet.
The bigger block is the interface. Claude Code got it close enough to use, not close enough to like. The remaining distance is all pixel-level polish, and closing that gap through prompts is the worst part of this entire workflow. Every correction is a negotiation. At some point you have to open the code yourself, and I haven't made that time yet.
The idea earned a second version. The second version earned a third pass. It just hasn't happened.